
この記事では、2つの母分散の比に関する統計的検定について記載していますので、参考なればうれしいです。
母分散の比の検定は、この記事で完結して解説していますが、統計的検定の概念とメリット、登場する用語の意味など、統計的検定(その1)の記事から段階を追って説明しています。
さまざまな検定の種類を網羅的に学習したい方は、ぜひ最初から読んでみてください。
https://qctoranomaki.com/sqc/statistical-testing/step1/
F分布とは?
定義
2つの母分散の比の検定を行うには、F分布を使います。
「F分布って聞いたことない」
「数式がむずかしすぎてサッパリ・・」
「聞いたことあるけど、何のために使うの?」
このような悩みや疑問をお持ちの方、心配する必要はありません。
F分布の「F」は統計学者フィッシャーに由来するもので、まさに母分散の比の区間推定や検定、分散分析を行うために用いられます。
確率密度関数は非常に複雑ですが、全く覚える必要はありません。
ほとんどの方にとっては、区間推定や検定に用いる統計量「F」の定義の式のみ覚えればよく、その式の構成も非常にシンプルです。
まずは概念だけ覚えておけば十分ですので、できるだけ簡単に順を追って説明しておきます。
F分布で用いるF値は以下の数式で定義されます。
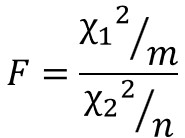
$χ^{2}$はカイ二乗値、$m$は第一自由度、$n$は第二自由度を表します。
まず、F分布を学習する前の予備知識として、カイ二乗分布を理解しておく必要がありますので、合わせてご覧ください。
https://qctoranomaki.com/sqc/statistics/chisqdist/
カイ二乗分布は、標準正規分布を基にした確率変数の二乗和が従う確率分布です。
F分布とは、そのカイ二乗分布に従う2つの確率変数の二乗和をそれぞれの自由度で割って比で表したF値が従う確率分布のことを意味します。
何だか関係性が複雑な感じですが、F分布の元である2つのカイ二乗分布は、それぞれ正規分布に従うというのは、すなわち、2つの正規分布の分散の比を扱う場合にF分布を用いるということです。
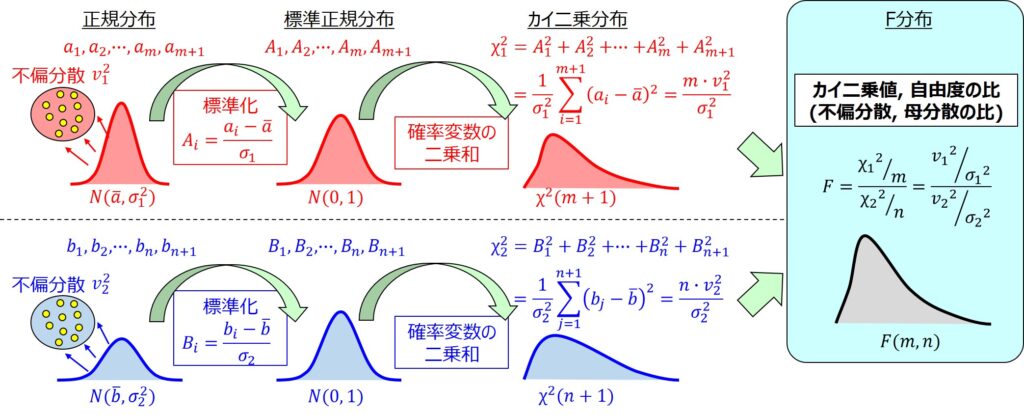
関係性を理解しておけば忘れないよ
F分布については、以下の記事で詳しく解説していますので、合わせてご覧ください。
https://qctoranomaki.com/sqc/statistics/f-dist/
また統計的検定では、区間推定と似た考え方を用いており、検定統計量の計算式も区間推定で登場した式と近いものが多いので、検定と推定はセットで覚えておくとよいです。
母分散の比の区間推定については、以下の記事で詳しく解説していますので、合わせてご覧いただければと思います。
https://qctoranomaki.com/sqc/estimation/part3/
F分布の特徴
区間推定や検定に使える便利な性質を紹介しておきます。
確率変数$X$が自由度$(m, n)$のF分布に従うとき、確率変数の逆数$1/X$は自由度$(n, m)$のF分布に従います。
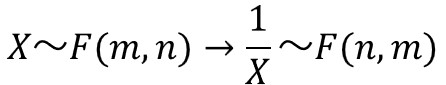
これは後ほど説明するF分布表を用いて上側(右側)確率を求める際に活用できる性質です。
F分布表では、一般的に5%や1%の上側確率に該当するF値が記載されています。
しかし、逆に95%や99%に該当する確率を求めたい場合には、これらの表から値をそのまま読み取るだけではいけません。
このような場合に上記の性質を用いれば、自由度を入れ替えて確率変数の逆数を取ることで、下側確率に変換することができるのです。
母分散の比の検定
早速、具体的な題材を用いて、実際にやってみましょう。
とある工場で作る加工部品に関して、強度のばらつきの大きいことが問題になっており、製造工程を改善してばらつきを抑える対処を施しました。工程変更前後の製品をそれぞれ10個抜き取り、変更前の不偏分散が15、変更後の不偏分散が5であったとき、変更前後の強度ばらつきに違いがあると言えるでしょうか?
検定統計量
F分布では、2つのカイ二乗分布の自由度と信頼度を設定すれば、全体の何%を占めているのか対応する確率が決まっており、エクセルのF.DIST関数やF分布表で簡単に求められます。
そして、このF値を検定統計量として用いることで、母分散の比に対する検定を行うことができるのです。
検定統計量の計算式は、以下のように表されます。
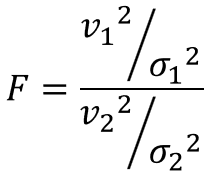
$σ_{1}^{2}$、$σ_{2}^{2}$は母分散、$v_{1}^{2}$、$v_{2}^{2}$は不偏分散を表します。
検定の際には、帰無仮説として母分散が同じ($σ_{1}^{2}=σ_{2}^{2}$)とするので、実際には以下の式を用いて計算します。
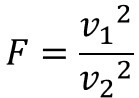
すごく簡単な式になったね
検定の手順
1.仮説を設定する
まずは、検証したい目的に合致した帰無仮説$H_{0}$と対立仮説$H_{1}$を設定します。
変更前後の分散に差があることを背理法で証明したいので、帰無仮説を「$H_{0}:σ_{1}^{2}=σ_{2}^{2}$」、すなわち「変更前後の母分散に違いがない」と設定します。
ここで、変更前と変更後、どちらを$σ_{1}$と$σ_{2}$に設定すれば良いのか、注意が必要です。
F値は自由度が大きくなるにつれて減少しますが、自由度が$∞$の場合に1に収束します。
つまり、1以上の値しかとらないので、分散の大きい方を分子に設定するようにしましょう。
今回の場合、$σ_{1}^{2}$は変更前の不偏分散、$σ_{2}^{2}$は変更後の不偏分散となります。
また、対立仮説は本来の目的である証明したい仮説として、「変更前後の分散に違いがある」とします。
$H_{0}:σ_{1}^{2}=σ_{2}^{2}$
$H_{1}:σ_{1}^{2}≠σ_{2}^{2}$(両側検定)
対立仮説を「$H_{1}:σ_{1}^{2}>σ_{2}^{2}$(変更後の分散が小さくなった)」と設定した場合には、片側検定となるので間違えないように注意しましょう。
2.検定統計量を算出する
先ほどの数式に従い、検定統計量を求めます。
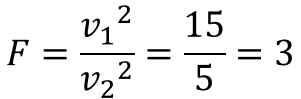
3.帰無仮説の棄却/採択を判定する
検定統計量の値から帰無仮説の棄却/採択を判定します。
判定の指標には、F値を用います。
通常、統計的検定では、有意水準$α=0.05$や$α=0.01$を基準として用います。
標準正規分布やt分布と違って注意が必要なのは、F分布は横軸0を中心とした左右対称の確率分布ではないことです。
この場合、1つの母分散の検定(カイ二乗分布)と同様に、上側確率と下側確率のそれぞれに対して棄却域を設定して判定することになります。
下側確率を求める場合は、先ほどの逆数の式を用いて変換します。
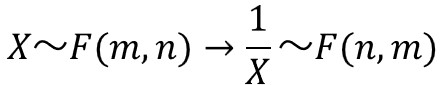
・・・あれ?
F値が1より大きくなるように分母と分子を設定したのに、逆数を取ると棄却域の値が1より小さくなってしまいますね。
つまり、分散の大きい方を分子に設定したことで、下側確率を判定する必要がなくなるのです。
そのため、今回の場合は、上側2.5%、0.05%に該当するF値を求めて棄却域の判定値とします。
サンプルサイズがともに10なので、自由度$m=9$、$n=9$となり、F分布表から$(m, n)=(9,9)$、確率$p=0.025$及び$p=0.005$となる値を読み取ります。
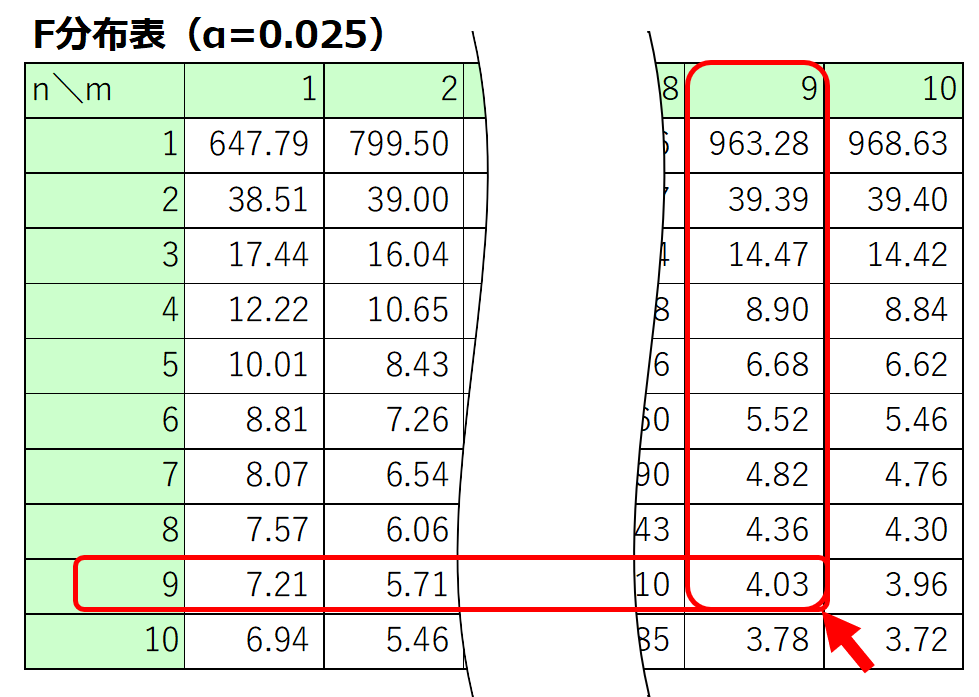
また、エクセルの場合には、F分布の累積分布関数の逆関数を表すF.INV.RT関数で右側確率(上側確率)を求められます。
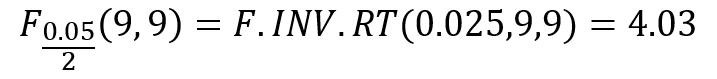
先ほどの検定統計量と比較すると、以下の関係であることが分かります。
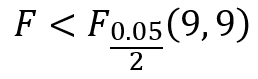
5%の棄却域に入らない状態、つまり帰無仮説が採択される結果となります。
4.検定の結論を導く
検定の結果から、今回の結論を出します。
「変更前後の分散に違いがあるとは言えない」
まとめ
- 2つの母分散の比に関する検定統計量
⇒不偏分散の大きい方を分子に設定したF値を用いる
下側確率の棄却の判定は不要(F値<1) - 検定の手順
⇒仮説を設定する
検定統計量を算出する
帰無仮説の棄却/採択を判定する
検定の結論を導く
最後まで読んでいただき、ありがとうございました。


コメント