

「指数分布ってどのような分布なの?」
「期待値と分散の計算の仕方を知りたい」
「エクセルでグラフ化したい」
このような疑問や悩みをお持ちの方に向けた記事です。
指数分布とは、とある事象の発生間隔を表す連続型の確率分布です。
例えば、とある店の来客の間隔や、とある製品が壊れる間隔、次に電話が鳴るまでの時間など、身近な事例に活用されることも多く、時間を確率変数に取ることが特徴です。
この記事では、指数分布の定義、ポアソン分布との違い、期待値と分散の導出の仕方、エクセルでグラフ化する手順について解説しています。
初心者の方にもわかりやすいよう、できるだけ細かく手順を踏んで説明しますので、参考になればうれしいです。
指数分布とは?
確率密度関数を表すと以下のようになります。
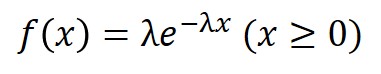
$e$はネイピア数(自然対数の底)、$λ$は所定の期間における平均の発生回数を表し、「パラメータ$λ$の指数分布に従う」「$X~Exp(λ)$」と表現されます。
指数分布における確率変数$X$は、連続的な値を取る計量値です。
このような連続型の確率分布における発生のしやすさを表した関数のことを確率密度関数と呼び、$f(x)$として表されます。
連続型確率分布や確率密度関数ついては、別の記事で詳しく解説していますので、合わせて参考にしていただければと思います。

ちなみに、指数分布は連続型の分布ですが、時間の間隔をパラメータとするため、確率変数が0より小さい場合の確率密度関数の値は0となります。
平均回数から時間を求められるなんて便利だね
ポアソン分布との違い
ポアソン分布とは、単位時間に平均$λ$回発生する事象が、単位時間に$k$回起こる確率を分布に表した離散型の確率分布で、確率質量関数は以下の式で定義されます。
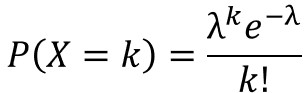
難しそうな表現ですが言い換えると、とある所定の期間の間にイベントが発生する回数の確率を表した分布のことです。
稀な事象の発生確率を求める場合に活用され、事故や火災、製品の不具合など、身近な事例も数多くあります。
混同しがちですが、指数分布が時間をパラメータにした連続型の分布に対し、ポアソン分布は回数をパラメータにした離散型の分布であることが大きな違いです。
ポアソン分布については、別の記事で詳しく解説していますので、合わせてご覧ください。

期待値と分散の導出
指数分布における期待値$E(X)$と分散$V(X)$は、以下となります。
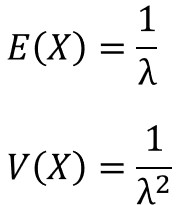
少し難しいですが、導出過程に興味のある方は参考にどうぞ。


期待値に関しては、指数分布の定義から、もっと直感的に考えることもできます。
単位時間に平均$λ$回の事象が起こるということは、1回の事象が平均$1/λ$の時間に起こっていると解釈できます。
期待値は、確率の平均値を意味するので、$E(X)$が$1/λ$になることが何となく理解できますね。
期待値が先に分かっていて、λを逆算するケースもあるよ
なお、$E(X)$と$V(X)$の意味、$V(X)$の導出の過程については、別の記事で解説していますので、合わせてご覧ください。

エクセルでのグラフの書き方
エクセルでの指数分布の確率の求め方、グラフの書き方を紹介します。
EXPON.DIST関数を用いれば、確率密度関数を計算することができます。
DISTというのは、分布(distribution)の略で、EXPONは指数を表すexponentialの略で、これを繋げた名前が関数名になっています。
使い方は簡単で、次の3つの変数を指定するだけです。
①:時間間隔($x$)
②:平均回数($λ$)
③:関数形式(TRUE or FALSE)
③の関数形式については、確率密度関数を求めたい場合はFALSE、累積分布関数を求めたい場合はTRUEを選択しましょう。
累積分布関数とは、確率変数がある値以下となる確率の関数のことで、以下の数式で定義されます。
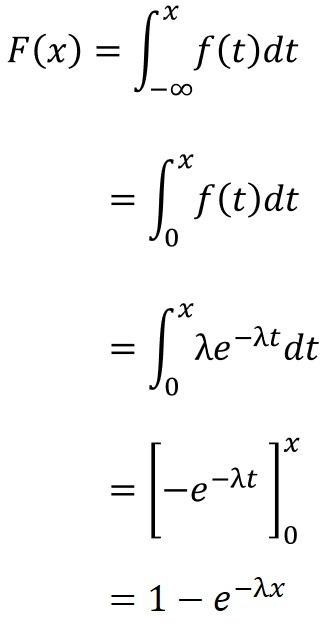
例えば、$λ=3$として、確率密度関数$f(x)$を求めると以下のようになります。
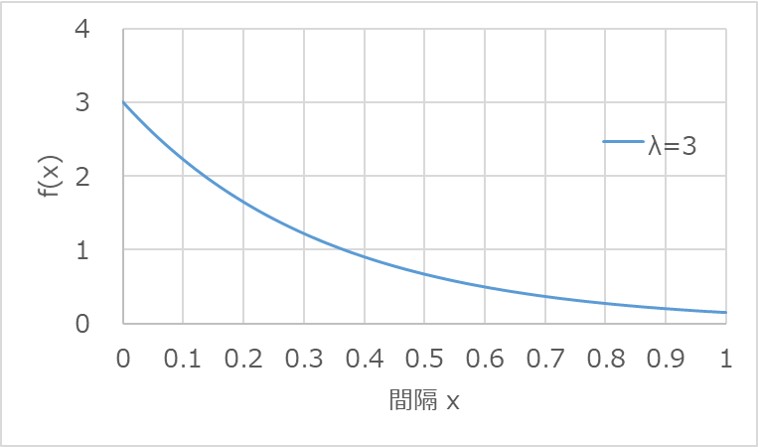
また、同様に累積分布関数$F(x)$を求めると以下になります。
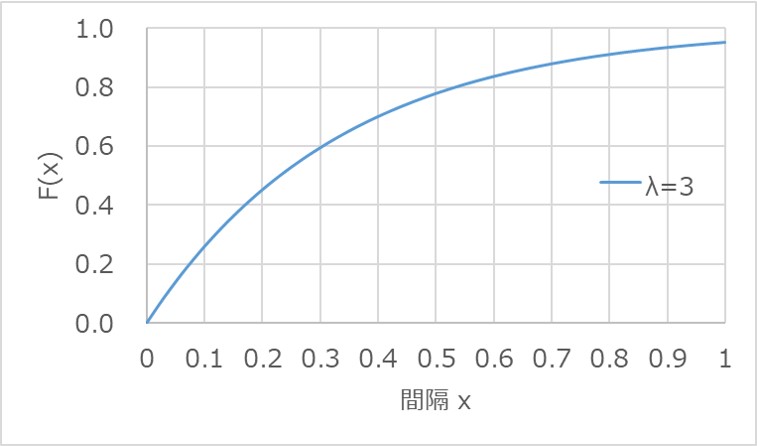
累積分布関数は、確率変数xの値が大きくなるにつれて、1に収束することが見て取れます。
これは、確率の合計値が1になることを表しており、この性質がグラフからも分かります。
指数分布のグラフの特徴
常に単調減少を示す
先ほどの確率密度関数$f(x)$のグラフから分かるように、間隔$x$の値が大きくなるにつれて、確率密度は減少する傾向を示します。
これは、指数分布の定義である「次に起こるまでの間隔」の意味を考えると、単調減少の理由が納得できます。
「次に起こるまで」ということは、裏を返すと「その時間までは発生しない」ことを意味します。
つまり、間隔$x$の値が大きくなるほど、そこに至るまでの時間において、「発生しない」状態が続くことになります。
具体的に説明すると、$x=1$における$f(x)$の値は、$0≤x<1$の区間で発生しない状態と、$x=1$において発生する状態を掛け合わせて成り立つことになります。
同じように、$x=5$として考えると、$0≤x<5$の区間で発生しない状態と、$x=5$において発生する状態の掛け算になります。
このように考えると、$a<b$において、$f(a)>f(b)$の関係が成り立つことが感覚的に分かりやすくなったのではないかと思います。
感覚的にイメージが合うと覚えやすいね
λの値で傾斜が変わる
平均回数$λ$の値の違いによって、分布形状がどのように変化するのか見てみましょう。
以下は、$λ$を1から10まで変えた場合の指数分布のグラフです。
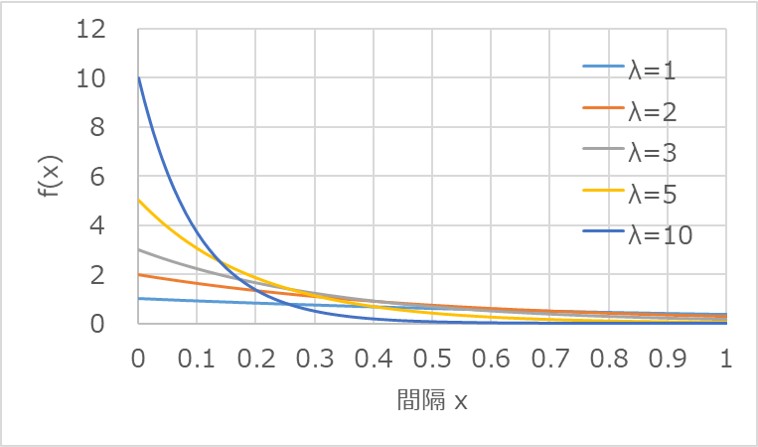
$x=0$における$f(x)$の値は$λ$となり、当然、縦軸の上から$λ$の大きい順に並んでいることが分かります。
注目すべきは、各系列のグラフが交差する箇所で、$λ$が大きいほど減少の傾斜が急峻で、早い段階で$f(x)$の値が0付近に収束していることが分かります。
反対に、$λ$の値が小さい場合には、緩やかな減少傾向を示し、なかなか$f(0)$の値が収束しないことが見て取れます。
これは、$λ$の値が大きく、発生頻度の高い状態の方が、次に発生するまでの間隔が短くなる確率が高いことを表しており、感覚的なイメージと結びつくかと思います。

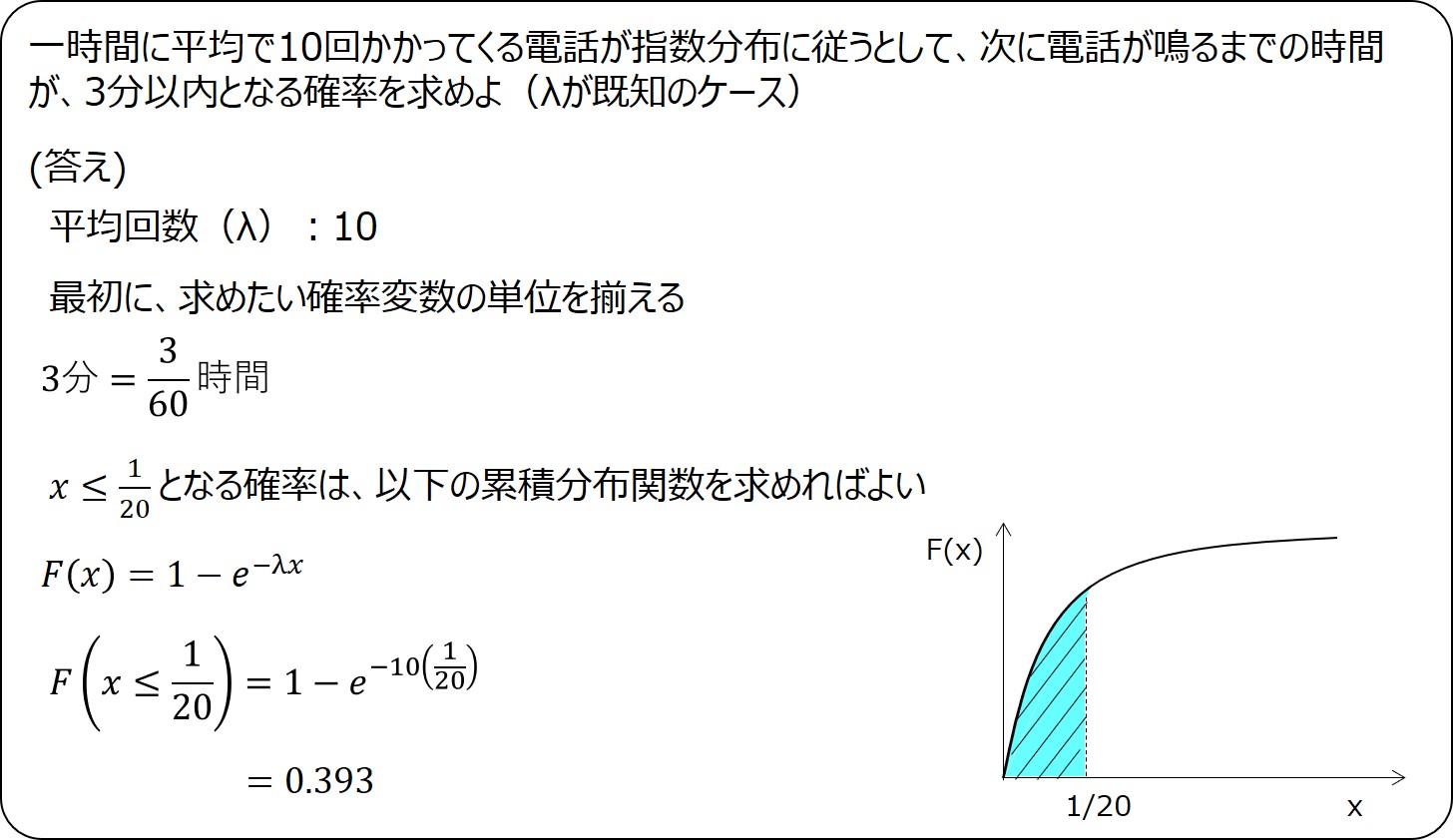
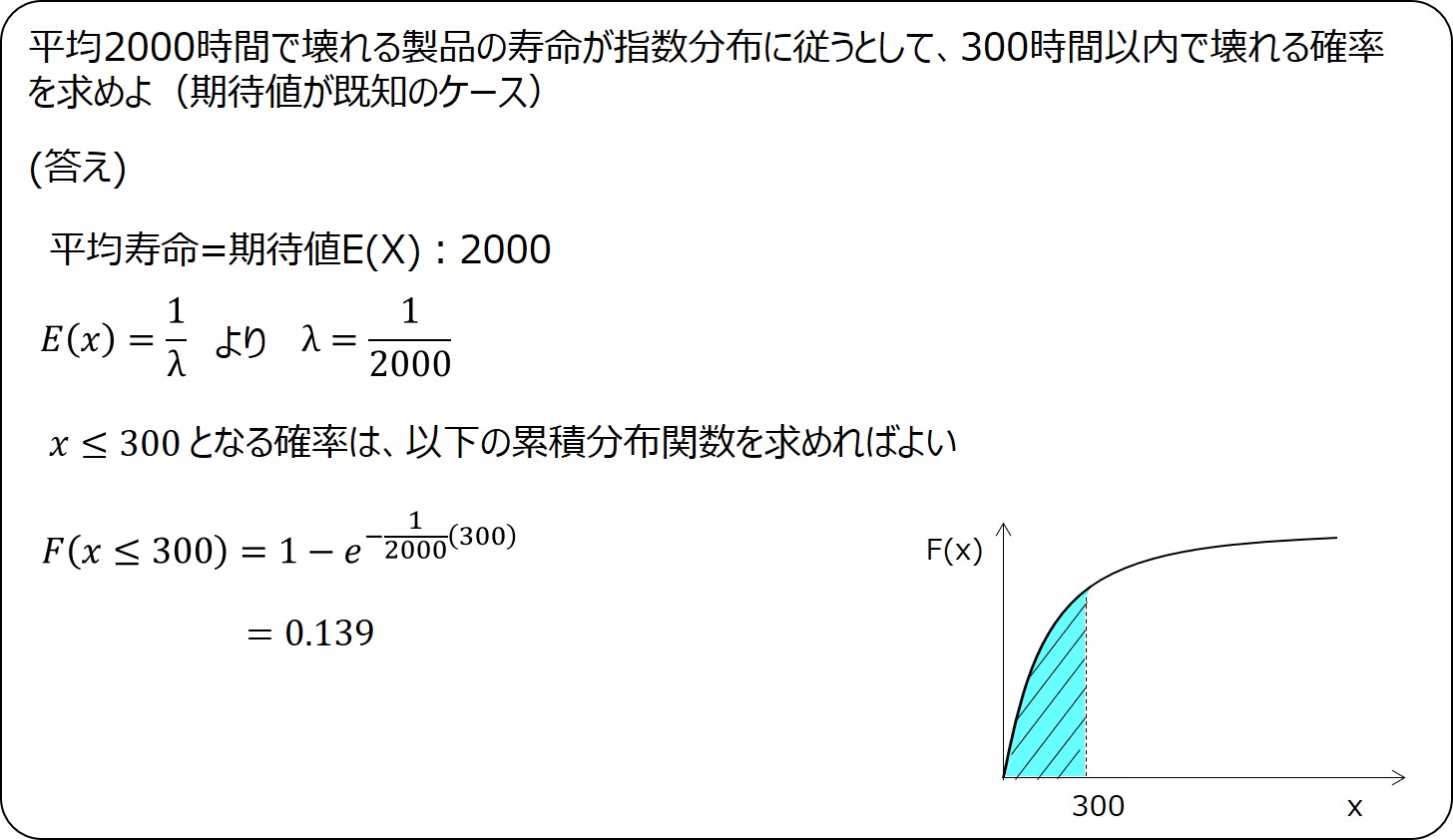
例題
まとめ
- 指数分布
⇒事象の発生間隔を表す連続型の確率分布
⇒とある店の来客の間隔や、とある製品が壊れる間隔、次に電話が鳴るまでの時間など - ポアソン分布との違い
⇒指数分布:時間をパラメータにした連続型の分布
⇒ポアソン分布:回数をパラメータにした離散型の分布 - 期待値
⇒$1/λ$ - 分散
⇒$1/λ^{2}$ - エクセルでの求め方
⇒EXPON.DIST関数で、確率密度関数と累積分布関数を計算できる
次に○○が発生するまでの時間、というのは身近な事例も見つけやすいと思います。
普段、何気なく気になっていた事象を興味本位で計算してみると結構面白いので、ぜひ試してみてください。
最後まで読んでいただき、ありがとうございました。
この記事で紹介した指数分布は、統計的品質管理を実践する上での基本要素の一つです。
製造業に携わるエンジニアであれば、その他の統計的手法はもちろんのこと、品質管理、生産の基礎知識を幅広く身につけておく必要があります。
社内講座などの機会が設けられている場合は、ぜひ若手のうちから積極的に活用して受講することをおススメします。
ただ、多くの社員を対象とする社内講座の場合、皆さん一人ひとりのレベルに適した学習ができない場合もあります。
忙しい日々の限られた勉強の時間を最大限に活かすためにも、自分の教育プランは自分で管理することを意識して、能動的に学習することも検討してみてはいかがでしょうか。



コメント